Qwen-AgentWorld:让 AI 自己模拟世界,自己在里面练
6 月 24 日,阿里 Qwen 团队在 X 上发了一条推文,宣布了一个新东西:Qwen-AgentWorld。
名字听起来像是又一个 Agent 框架,但看了论文之后发现,思路跟市面上所有 Agent 项目都不一样。
它在做什么?
一句话:训练一个模型来模拟环境,而不是训练一个模型在环境里做事。
现有的 Agent 训练路径是:LLM → 接工具 → 在真实环境里跑 → RL 微调。瓶颈很明显——真实环境太慢、太贵、不可控。你要训一个会操作浏览器的 Agent,就得真的开浏览器、真的加载网页、真的等响应。
Qwen-AgentWorld 反过来想:如果模型能预测「我做了 X 动作后,环境会返回什么」,那就不需要真的跑环境了。模型自己就是环境。
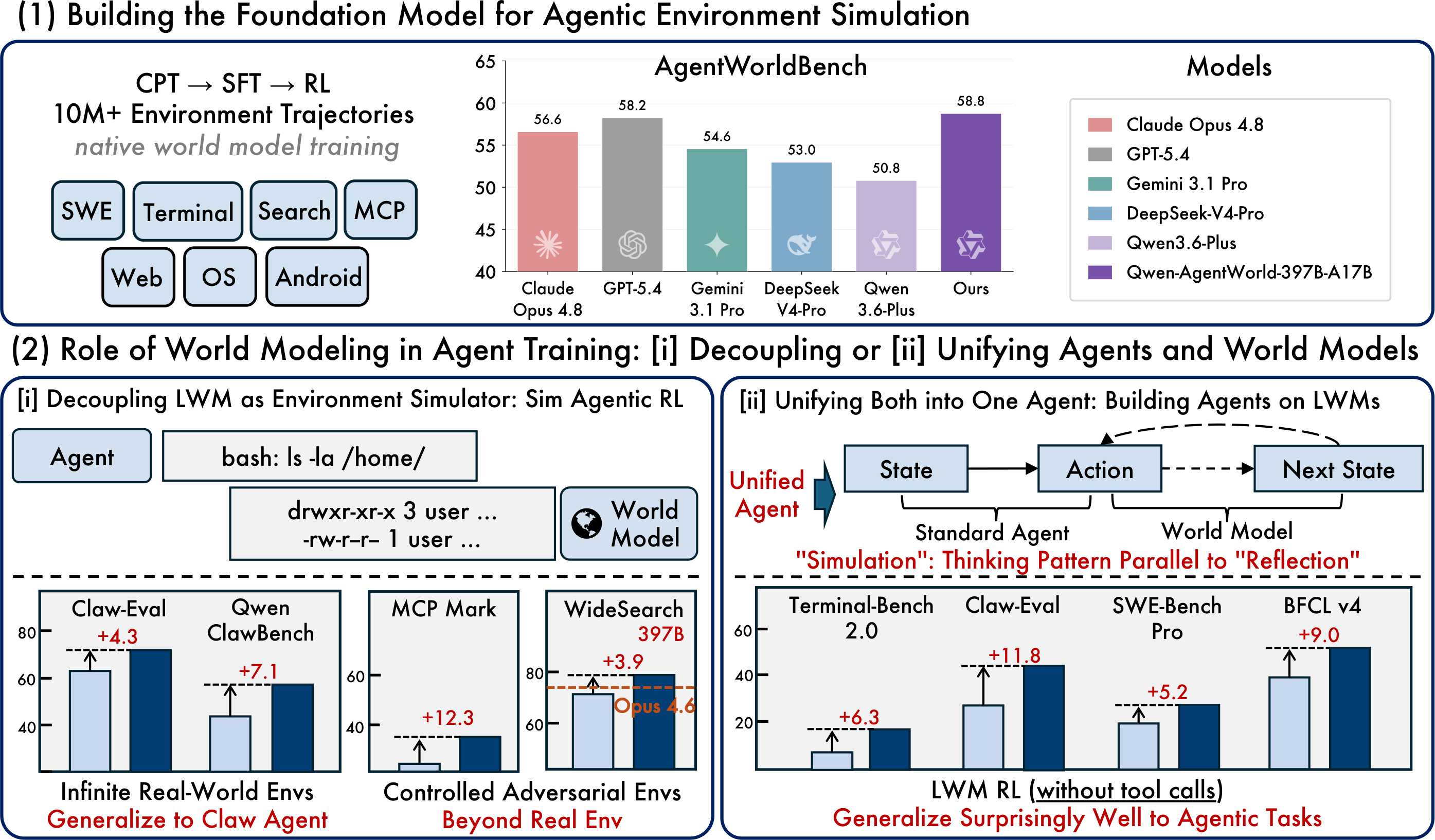
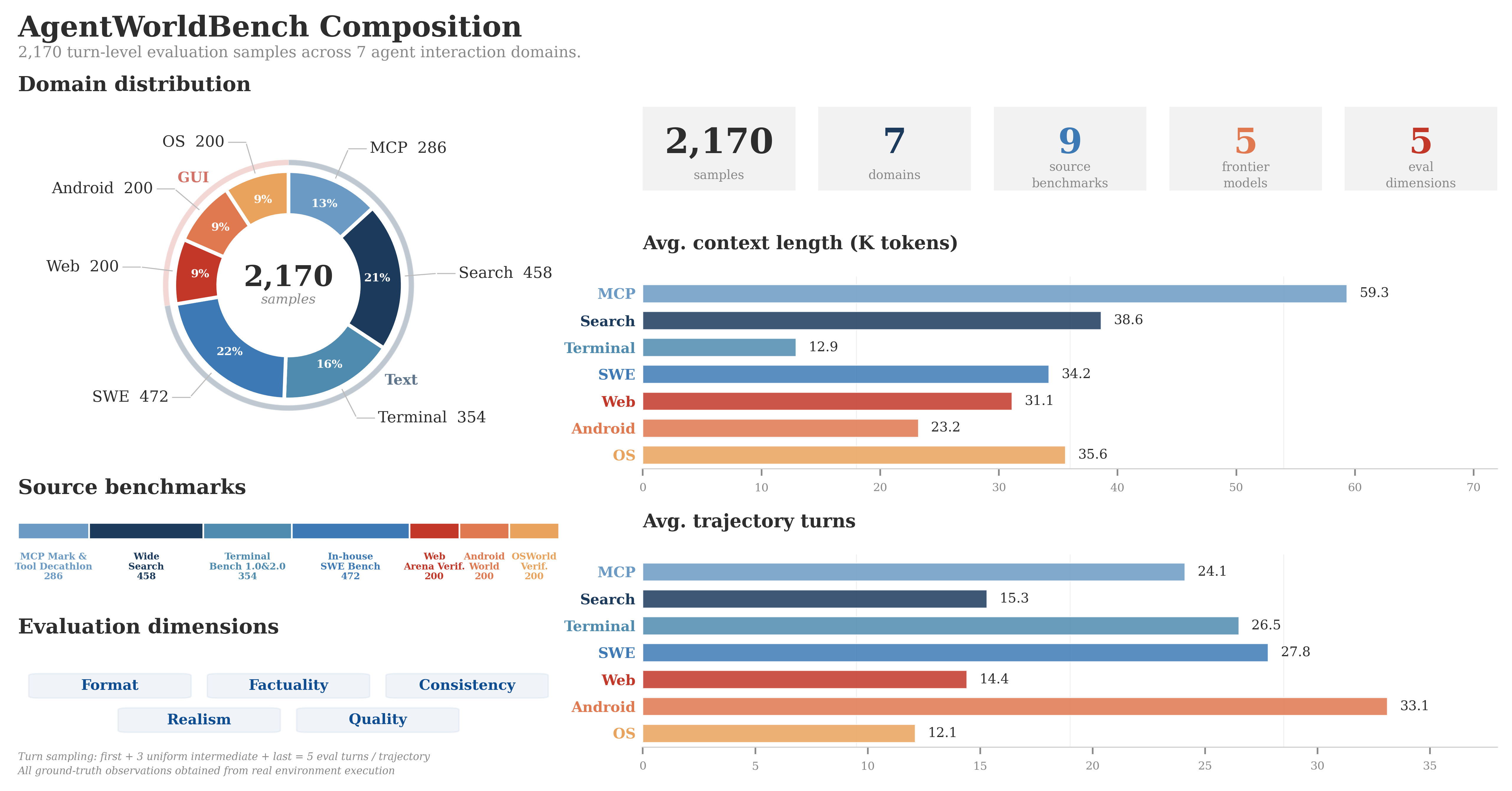
覆盖 7 个领域:MCP(工具调用)、Search(搜索)、Terminal(终端)、SWE(软件工程)、Android(安卓)、Web(浏览器)、OS(操作系统)。一个模型,七个环境。
怎么训练的?
论文标题是《Language World Models for General Agents》,三位一体的训练流程:
第一阶段 CPT(持续预训练):用超过 1000 万条真实环境交互轨迹,让模型学会「状态转移」——给定当前状态和动作,环境会变成什么样。
第二阶段 SFT(监督微调):激活模型的 next-state-prediction 推理能力,让它学会用长链式思考(long CoT)来模拟环境响应。
第三阶段 RL(强化学习):用混合 rubric + rule 奖励来提升模拟的保真度。
关键区别:环境建模不是事后的补丁,是从 CPT 阶段就开始的核心训练目标。论文里反复强调「native world model」这个词。
跑分数据
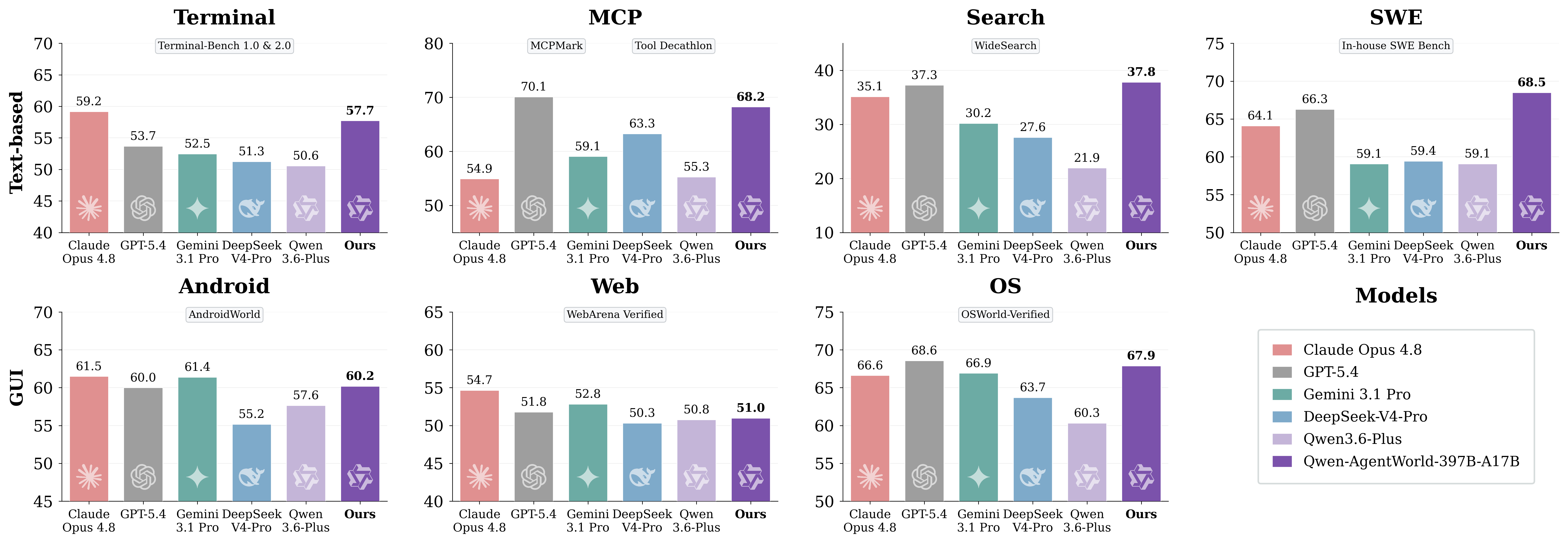
Qwen 团队同时发布了 AgentWorldBench,一个专门评估语言世界模型的基准。数据来自 5 个前沿模型在 9 个 benchmark 上的真实交互轨迹,覆盖 7 个领域。
关键数字:
| 模型 | 总分 |
|---|---|
| Qwen-AgentWorld-397B-A17B | 58.71 |
| GPT-5.4 | 58.25 |
| Claude Opus 4.8 | 56.59 |
| Claude Opus 4.6 | 57.80 |
| Gemini 3.1 Pro | 54.57 |
| Qwen-AgentWorld-35B-A3B | 56.39 |
| Qwen3.5-35B-A3B(无 LWM 训练) | 47.73 |
397B 版本总分第一,超过了 GPT-5.4。更值得注意的是 35B-A3B 版本:只有 3B 活跃参数的 MoE,总分 56.39,跟 Claude Opus 4.8 差距不到 1 分。而同样架构但没有 LWM 训练的 Qwen3.5-35B-A3B 只有 47.73 分——世界模型训练带来了 +8.66 分的提升。
更有意思的两个发现
论文不只是「做了一个模型」,还探索了世界模型怎么帮助 Agent 训练:
发现一:模拟环境训练 > 真实环境训练
用 Qwen-AgentWorld 做模拟环境来跑 Sim RL(模拟强化学习),效果超过了在真实环境里训练。
| 训练方式 | Claw-Eval | QwenClawBench |
|---|---|---|
| Qwen3.5-35B-A3B(基线) | 65.4 | 47.9 |
| + Sim RL(用 Qwen3.6-Plus 做环境) | 66.7 | 47.8 |
| + Sim RL(用 Qwen-AgentWorld-397B 做环境) | 69.7 | 55.0 |
用世界模型做环境,比用真实环境多拿了 4.3 和 7.1 分。而且它还能做 zero-shot 泛化到从没见过的环境(比如 OpenClaw)。
更进一步:模型支持可控模拟——你可以往环境里注入扰动、构造虚构世界,让 Agent 在更难的条件下训练。比如在搜索任务里,Agent 完全在虚构的世界里训练,迁移到真实搜索任务后依然有效,F1 提升了 16.29 分。
发现二:学预测环境 = 变强
世界模型训练不只让模型会模拟环境,还能反过来提升 Agent 自身的能力。
论文做了一个实验:先用单轮的、非 Agent 的轨迹做 LWM RL warm-up,然后再测多轮工具调用的 Agent 任务。结果:
| Benchmark | 无 warm-up | 有 LWM warm-up | 提升 |
|---|---|---|---|
| Terminal-Bench 2.0 | 33.25 | 39.55 | +6.30 |
| SWE-Bench Verified | 64.47 | 67.86 | +3.39 |
| SWE-Bench Pro | 42.18 | 47.42 | +5.24 |
| WideSearch F1 | 33.38 | 46.17 | +12.79 |
| Claw-Eval | 53.60 | 64.88 | +11.28 |
| BFCL v4 | 62.29 | 71.25 | +8.96 |
其中后三个是完全 out-of-domain 的任务。也就是说,「学会预测环境」这个能力本身,会迁移到 Agent 任务上,即使没有任何 Agent 专项训练。
社区反应
这个工作在社区里引起了不小的讨论。
HN 上有人注意到一个细节:训练数据不是合成的,而是真的部署了物理主机和虚拟机(Ubuntu、macOS)来采集交互轨迹。有人讨论这个东西能不能用来做 Agent 测试环境的低成本替代——「以后不用真的开 Docker 跑测试了?」
Reddit r/LocalLLaMA 上 194 个 upvote,讨论集中在 35B-A3B 这个小模型能不能本地跑起来做 Agent 测试沙箱。3B 活跃参数的 MoE,理论上一张 24GB 显卡就能推理。
HuggingFace 上线一天,模型下载 223 次,收藏 143。
我的看法
这个东西最大的价值不是跑分第一(虽然也很厉害),而是它验证了一个方向:Agent 训练可以从「依赖真实环境」转向「自给自足」。
AlphaGo 通过自我博弈称霸围棋,是因为它不需要跟人类下棋来学习。Qwen-AgentWorld 试图做类似的事:Agent 不需要在真实环境里犯错来学习,它在自己模拟的世界里就能练出来。
如果这个方向成立,Agent 训练的成本会大幅下降。你不需要 1000 台浏览器实例来跑 Web Agent RL,一个模型就够了。
当然问题也存在:模拟器和真实环境之间一定有 gap。模型预测的环境响应跟真实的可能不一样,Agent 在模拟世界里学到的策略,迁移到现实可能有偏差。论文里提到了 zero-shot 泛化的能力,但实际效果还需要更多验证。
不过作为第一步,这个工作足够有意思。
开源信息
- 模型权重:Qwen-AgentWorld-35B-A3B(MoE,35B 总参数 / 3B 活跃,256K 上下文)
- 评测基准:AgentWorldBench(7 领域)
- 支持 SGLang 和 vLLM 推理
- 论文作者 30+ 人,第一作者 Yuxin Zuo,通讯作者包括 Ning Ding(清华大学)
397B-A17B 版本没有开源权重,只有 35B-A3B 开源了。
参考链接
论文:Qwen-AgentWorld: Language World Models for General Agents
https://arxiv.org/abs/2606.24597HuggingFace 模型
https://huggingface.co/Qwen/Qwen-AgentWorld-35B-A3BHuggingFace 数据集(AgentWorldBench)
https://huggingface.co/datasets/Qwen/AgentWorldBenchModelScope
https://modelscope.cn/collections/Qwen/Qwen-AgentWorld
本文标题:Qwen-AgentWorld:让 AI 自己模拟世界,自己在里面练
文章作者:AwesomeYang
发布时间:2026-06-25
最后更新:2026-06-25
原始链接:https://awesomeyang.com/2026/06/25/qwen-agentworld-language-world-model/
版权声明:未经允许禁止转载,请关注公众号联系作者
