一个人+Claude Code=投研团队:AI Berkshire为什么火了
如果你想买一只股票,打开 ChatGPT 问”帮我分析一下拼多多值不值得买”,你会得到一篇标准的”一方面…另一方面…”式分析。最后大概率以”投资有风险,请自行判断”收尾。
看起来什么都说了,但什么决策也做不了。
GitHub 上一个叫 ai-berkshire 的项目这周火了(+1270 星),它做的事情就是解决这个问题:让 AI 给出真正能用来做决策的投资研究,而不是两面讨好的废话。
核心卖点很直接——一个人 + Claude Code = 一个投研团队。
不是纸上谈兵
作者声称这套框架已经实盘验证了两年:
| 指标 | 2024 全年 | 2025 至今 |
|---|---|---|
| 本框架实盘 | +69.29% | +66.38% |
| 标普500 | +23.31% | +16.39% |
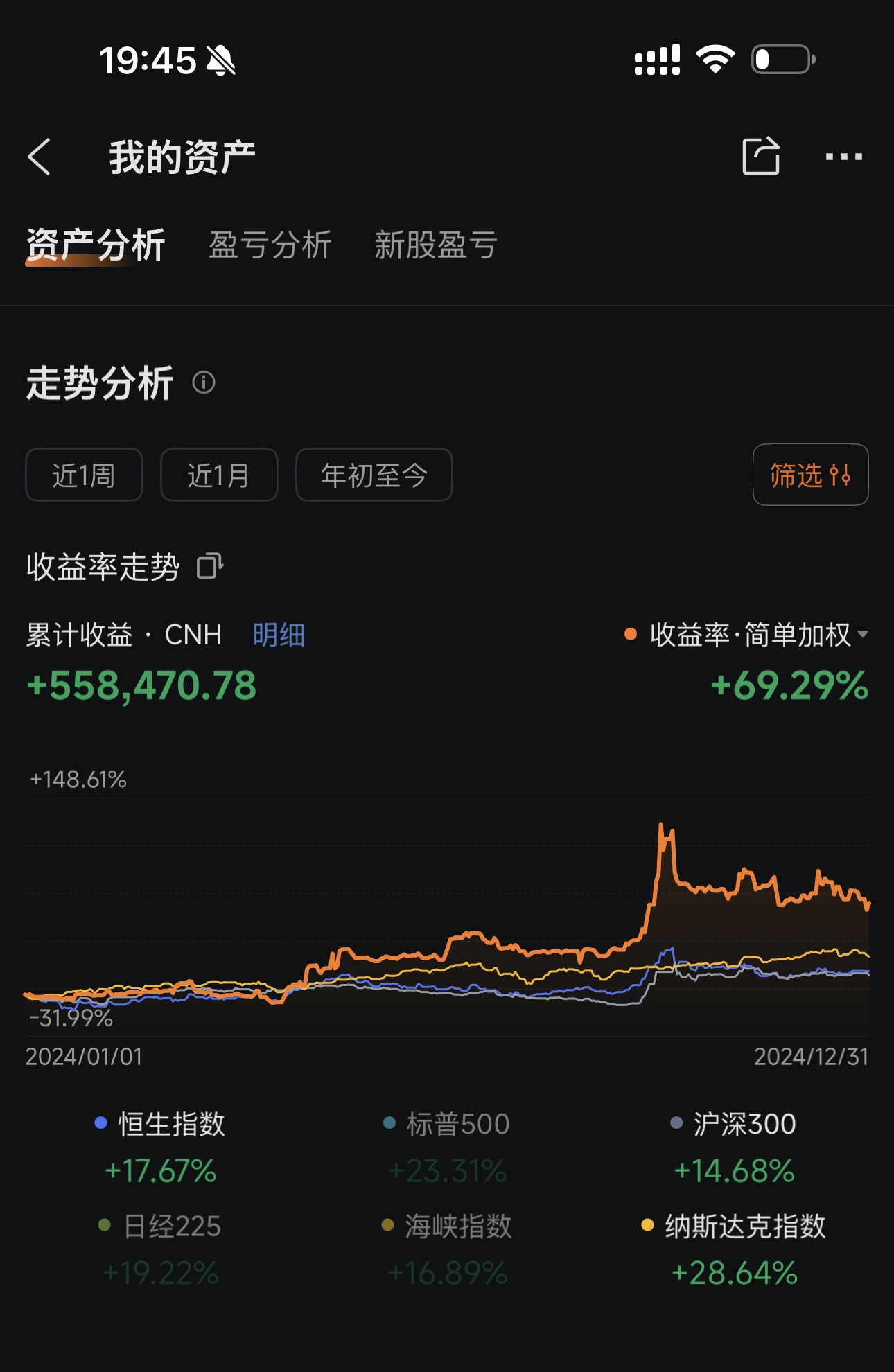
2024 年超额收益:跑赢标普 46 个百分点。2025 年至今跑赢标普 50 个百分点。
当然,历史收益不代表未来表现。但这个数据确实让人想看看它到底是怎么做的。
四大师方法论 + 多 Agent 对抗
AI Berkshire 的核心设计是把巴菲特、芒格、段永平、李录四位价值投资大师的方法论分别变成独立的 AI Agent。
以分析拼多多为例,四个视角会给出完全不同的判断:
- 段永平视角(商业模式):C2M 模式难以复制 → 评分 3.7/5
- 巴菲特视角(财务估值):扣现金 PE 仅 6.3x → 评分 4.4/5
- 芒格视角(逆向思考):护城河比想象中浅 → 评分 3.5/5
- 李录视角(长期确定性):管理层文化有隐患 → 评分 2.0/5
巴菲特说”真便宜”,李录说”不确定就不买”——这种冲突才是投资决策的真实状态。单一 prompt 无法制造这种多视角对抗。
最终输出不是”一方面…另一方面…”,而是强制给出明确的买卖建议和价格区间。
多 Agent 架构
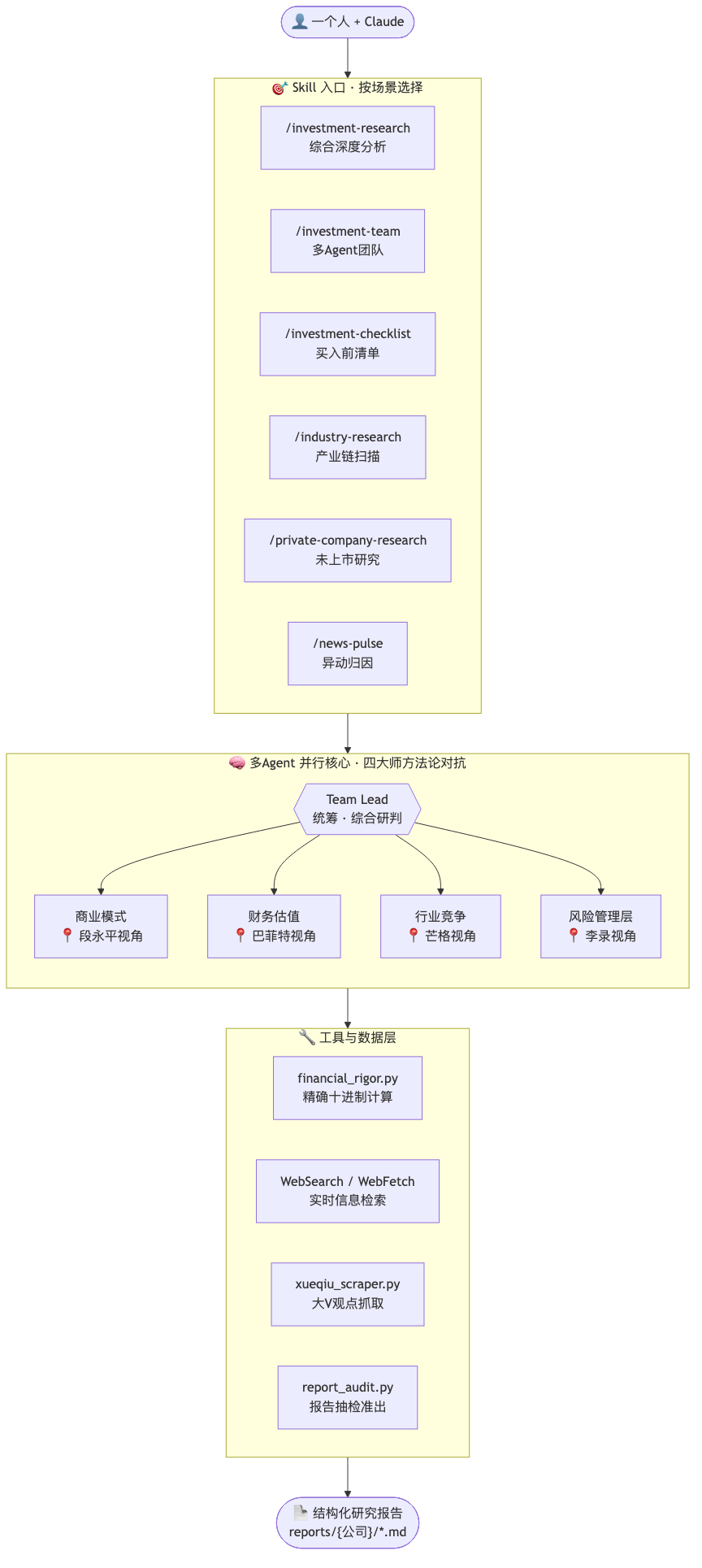
四个 Agent 各自独立:
- Agent 1:商业模式(段永平视角)
- Agent 2:财务估值(巴菲特视角)
- Agent 3:行业竞争(芒格视角)
- Agent 4:风险与管理层(李录视角)
每个 Agent 独立搜索网络、交叉验证数据、独立给出结论,最后由 Team Lead 综合。
和直接问 AI 有什么不同?
强制决策纪律。镜子测试——5 句话说不完整 = 不买,没有例外。
防”看起来很对”机制。内置多层验证:信息丰富度评级(A/B/C)、芒格式逆向检验、快速否决清单(8 条红线一票否决)、反共识检查。
精确计算。所有财务计算用 Python decimal.Decimal,不用 float。关键数据至少 2 个独立来源交叉验证。
16 个 Skill
整个框架包含 16 个 Skill,覆盖深度研究、财报分析、行业筛选、持仓管理四大类。
这种”把专家方法论编码成 AI 可执行的技能”的思路,不只适用于投资——任何需要专业判断的领域都能套用。
怎么用?
支持 Claude Code 和 Codex 两个平台:
1 | git clone https://github.com/xbtlin/ai-berkshire.git |
装完后在 Claude Code 里直接调:
1 | /investment-research 腾讯 |
参考链接
AI Berkshire 项目主页
https://github.com/xbtlin/ai-berkshireInvestSkill(类似项目)
https://github.com/yennanliu/InvestSkill
本文标题:一个人+Claude Code=投研团队:AI Berkshire为什么火了
文章作者:AwesomeYang
发布时间:2026-06-28
最后更新:2026-06-28
原始链接:https://awesomeyang.com/2026/06/28/ai-berkshire-claude-code-investment/
版权声明:未经允许禁止转载,请关注公众号联系作者
