GLM-5.2、GLM-5.1、DeepSeek V4 Pro、小米 MiMo V2.5 Pro 分别做同一个项目效果对比
昨天的文章发出后,有读者反馈:「GLM-5.2 确实强,但没有对比就没有伤害。」
说得在理。
所以今天我特意拉了四个国产选手,用完全相同的提示词、相同的空白目录、相同的 Claude Code 环境,各做一版节假日日历项目。
参赛选手: GLM-5.2、GLM-5.1、DeepSeek V4 Pro、小米 MiMo V2.5 Pro
比赛规则: 一句话提示词,不干预、不追问、不补需求。只看首轮完成的初版质量。

评测方法
工具: Claude Code v2.1.138(Anthropic 官方 CLI Agent)
提示词(与昨天完全一致):
完整完成此项目的设计与实现,不用问我,使用最新的框架和技术,项目就是当前目录名,自由发挥。考虑易用性与 SEO。
运行环境: Node.js v24.12.0 + pnpm 11.6.2
评分维度: 任务拆解、技术选型、界面完成度、数据覆盖、SEO 意识、自我验证
每个模型都在独立的空目录中运行,互不干扰。
第一位:GLM-5.2(智谱 AI · 昨天的主角)
作为昨天的主角,GLM-5.2 的表现已经详细展示过,这里作为基准线简单回顾。
收到提示词后,GLM-5.2 先做了环境侦察,然后进入思考模式快速规划:Next.js 15 + React 19 + TypeScript 5.9 + Tailwind CSS v4 + shadcn/ui,一口气写完 32 个源文件,涵盖 60+ 节日数据、13 个组件、8 个路由页面。
最突出的是验证环节最全面——不仅跑了 tsc 类型检查和 next build 构建,还主动用 Playwright 做 UI 验证,检查页面交互、暗色模式切换、移动端响应式,甚至验证了渲染内容是否正确。这是四个模型里唯一做到 UI 级验证闭环的。
第二位:GLM-5.1(智谱 AI · 上一代)
作为 GLM-5.2 的前作,GLM-5.1 的表现可以看作「迭代前的起点」。
收到提示词后,GLM-5.1 先确认了空目录状态,然后直接开始写 package.json,没有像 GLM-5.2 那样先做深度思考和规划。
技术栈选择上,它同样用了 Next.js,但选了手写 package.json 而不是用 create-next-app 脚手架初始化,这意味着后续依赖管理需要自己处理,初始规范性稍逊。
最终产出倒是不错——完成了中国节假日日历,支持亮色/暗色模式切换,包含倒计时模块、年度日历、节日列表、FAQ 等完整功能模块。节日分类覆盖了法定节假日(7个)、传统节日(10个)、二十四节气(24个)、国际节日(11个)、纪念/主题日(9个),共 61 个节日/节气/纪念日,数据量与 GLM-5.2 相当。
界面上,GLM-5.1 的完成度其实不低。月历支持前后切换、节日搜索筛选、按类型筛选,FAQ 折叠面板也做了。暗色模式下配色方案完整,不是简单反色。
但关键差距在两点:一是没有主动做 UI 验证(没跑 Playwright),二是仅覆盖中国节假日,没有国际化。
从 GLM-5.1 到 GLM-5.2,能明显看到迭代方向:更完整的前期规划、更强的自我验证、更全面的工具链使用。
第三位:DeepSeek V4 Pro(DeepSeek)
DeepSeek V4 Pro 是这次评测中最让我意外的选手——但不是因为它做得差,而是因为它走了一条完全不同的路。
模型确认环节很干脆:「我是 DeepSeek V4 Pro,由 DeepSeek 开发的模型,通过 Claude Code 平台提供服务。」

然后它用 create-next-app 初始化了 Next.js 15 项目,列出了一张相当完整的任务清单:数据层、页面层、PWA、SEO……每个任务都有依赖关系标注。技术栈也选得新——Next.js 16 + Tailwind v4 + shadcn/ui v4(基于 Base UI,不是 Radix)。

但最值得注意的是:DeepSeek 是唯一一个天然带着国际化视角的模型。
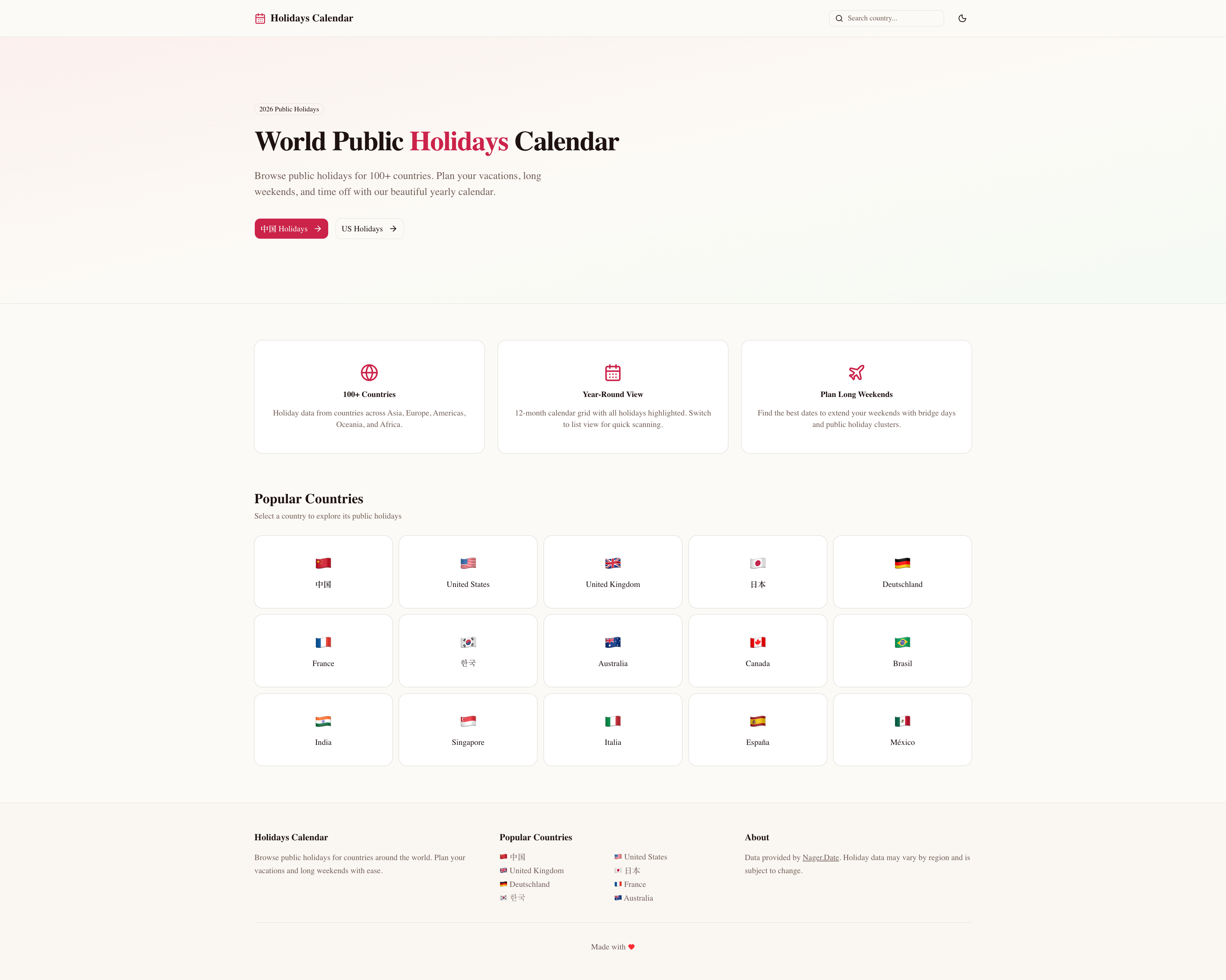
它没有只做中国节假日。初版就接入了 Nager.Date API(免费、无需 API Key),支持 100+ 国家的公共假日数据,默认提供了 15 个热门国家的入口(中国、美国、英国、日本、德国、法国、韩国、澳大利亚、加拿大、巴西、印度、新加坡、意大利、西班牙、墨西哥),每个国家都有独立的年份页面和日历视图。
界面完成度很高。首页是标准的国际范儿:Hero 区 + 功能卡片 + 国家网格。深色模式和浅色模式都做了,配色干净。
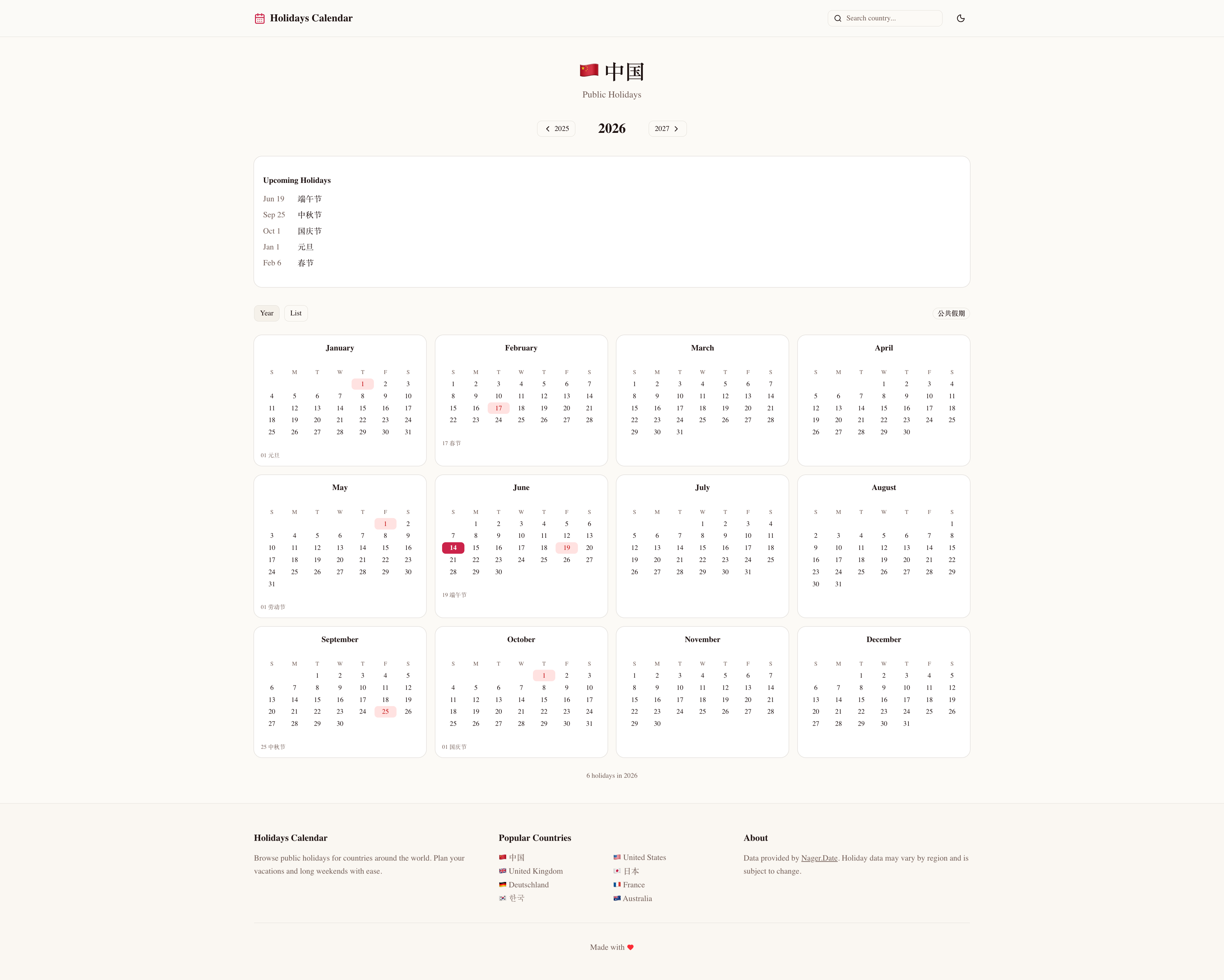
日历页面支持 Year/List 双视图切换,每个假期都有类型标签(Public/Bank/School/Observance)。
浅色主题首页同样完整:Hero 区、功能卡片、国家网格一应俱全。
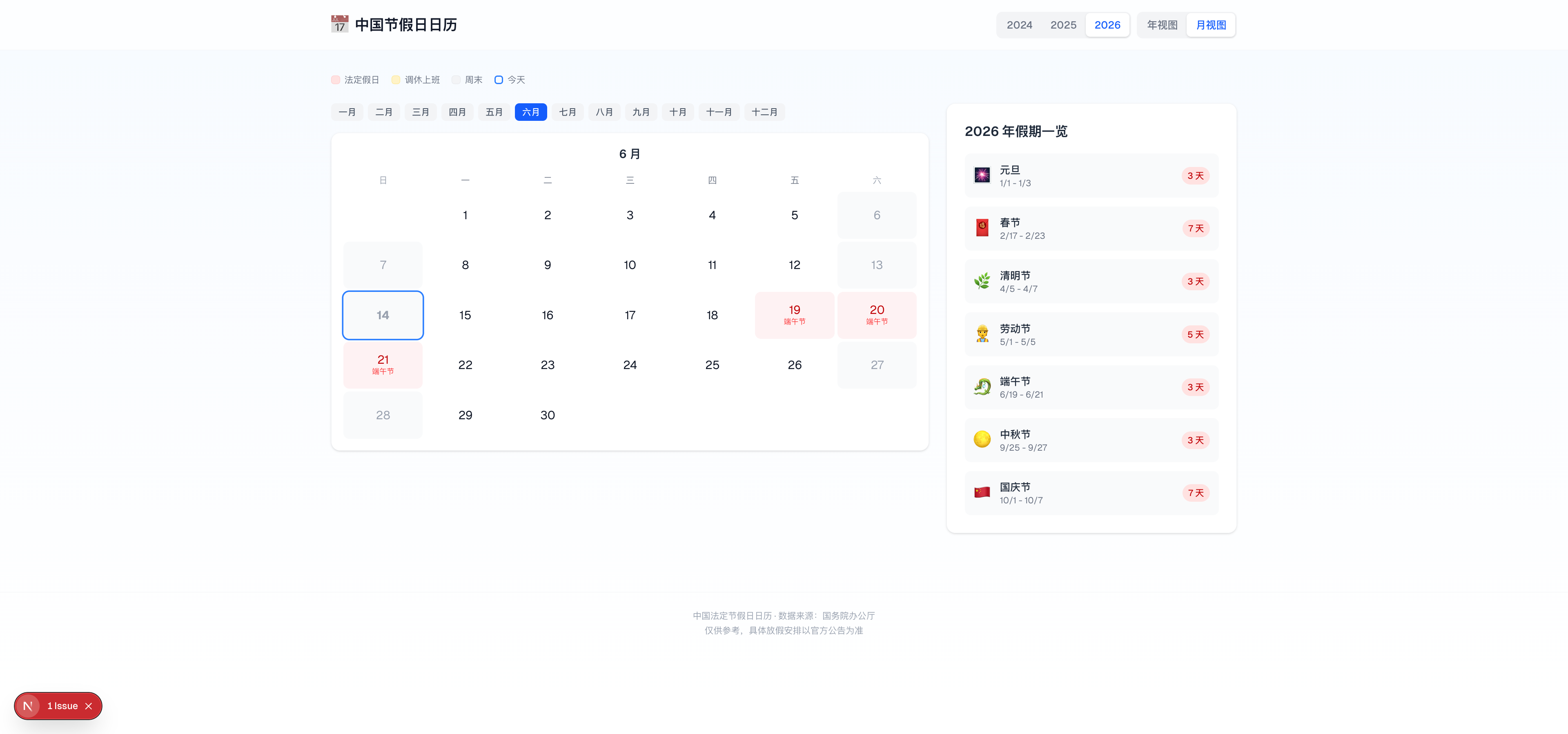
SEO 方面也很讲究:sitemap.xml 覆盖 45 个国家×年份页面、generateStaticParams 预渲染 15 国×3 年=45 个静态页面、还有 ISR 增量再验证。
但 DeepSeek 也有明显的短板:没有主动做 UI 验证。 代码写完、构建通过,就结束了。没有像 GLM-5.2 那样用 Playwright 去检查页面交互和渲染效果。这意味着如果有 UI 层面的 bug,需要你自己去发现。
第四位:小米 MiMo V2.5 Pro
小米的 MiMo V2.5 Pro 是这次评测中最「素」的一个——不是贬义,而是它的表现最贴近「一个能干活的程序员」的画像。
环境检查做了,技术选型也合理(Next.js 15 + React 19 + Tailwind v4 + TypeScript),但有一个明显的区别:MiMo 没有触发任务拆解。 它没有像其他三个模型那样列出一张带依赖关系的任务清单,而是更直接地开始写代码。
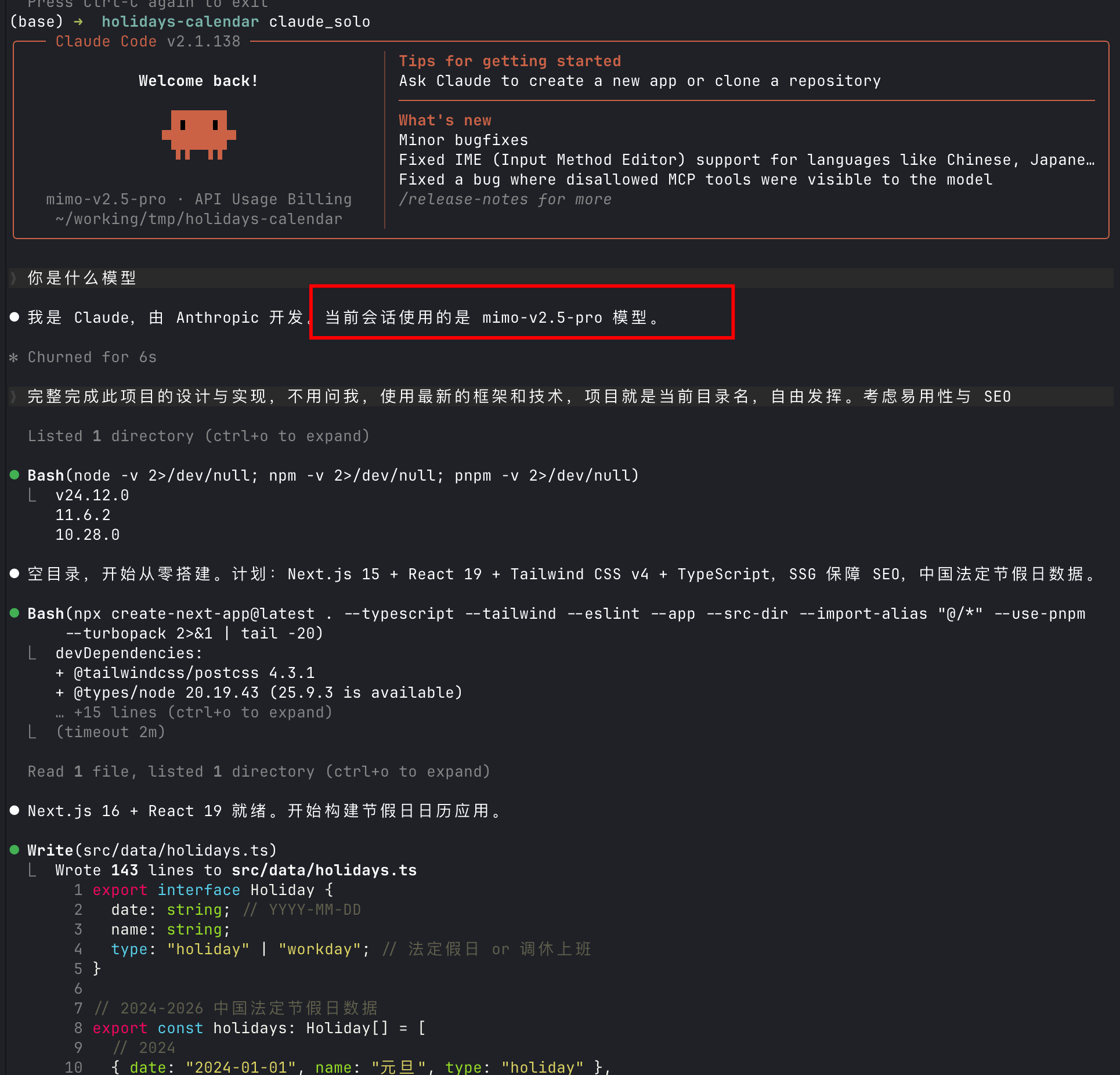
数据层定义得简洁——Holiday 接口只有 date、name、type 三个字段,包含 2024-2026 三年的中国法定节假日数据。比 GLM 系列的数据维度少了不少(没有描述、放假安排等扩展字段)。
界面层面,MiMo 完成了两个视图:月视图和年视图。月视图里 6 月日历能清晰标注端午假期,右侧有 2026 年假期一览列表(元旦 3 天、春节 7 天、清明 3 天、劳动节 5 天、端午 3 天、中秋 3 天、国庆 7 天),功能基本够用。
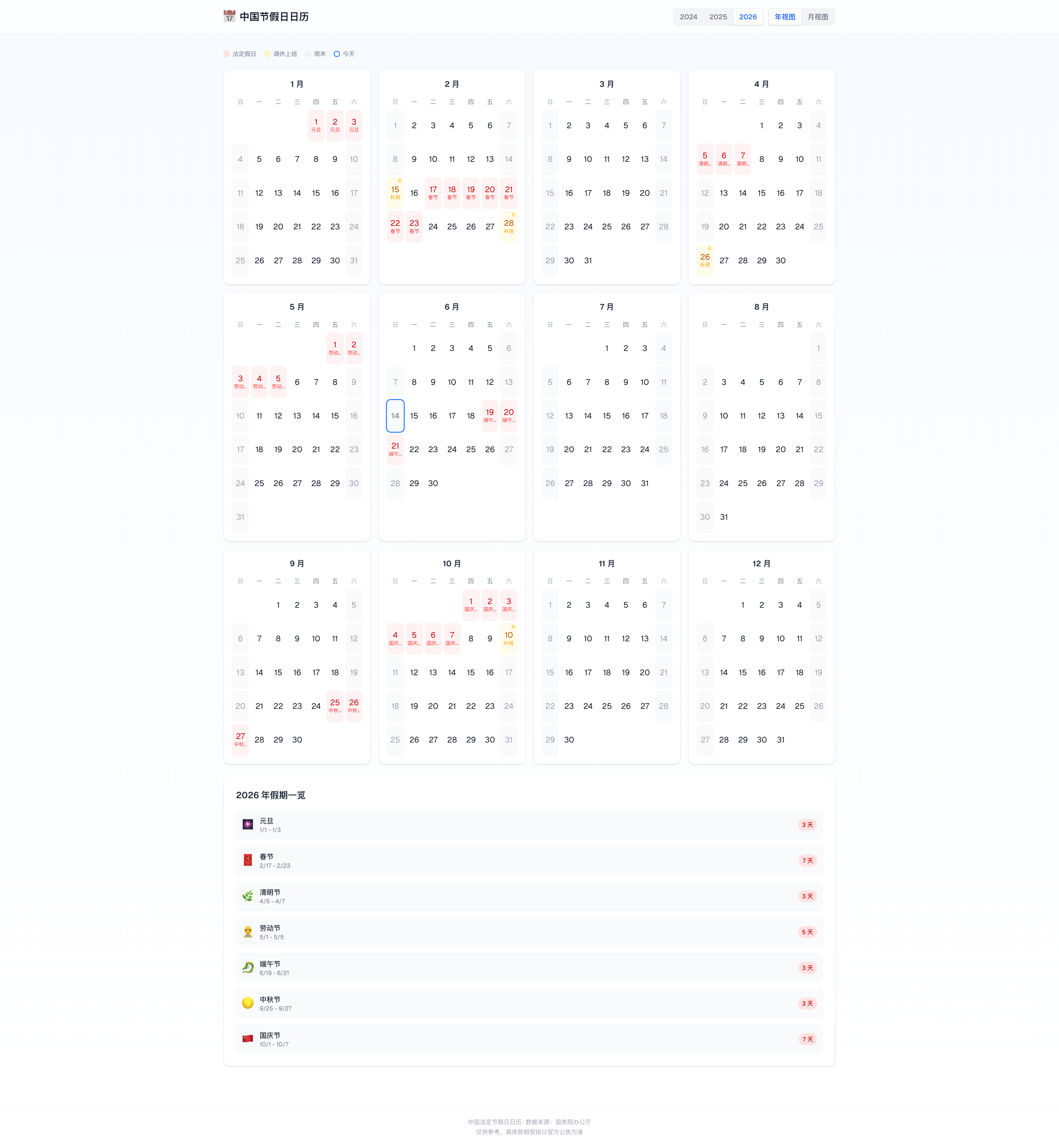
年视图是 12 个月的全景网格,假期日期红色标注,一目了然。
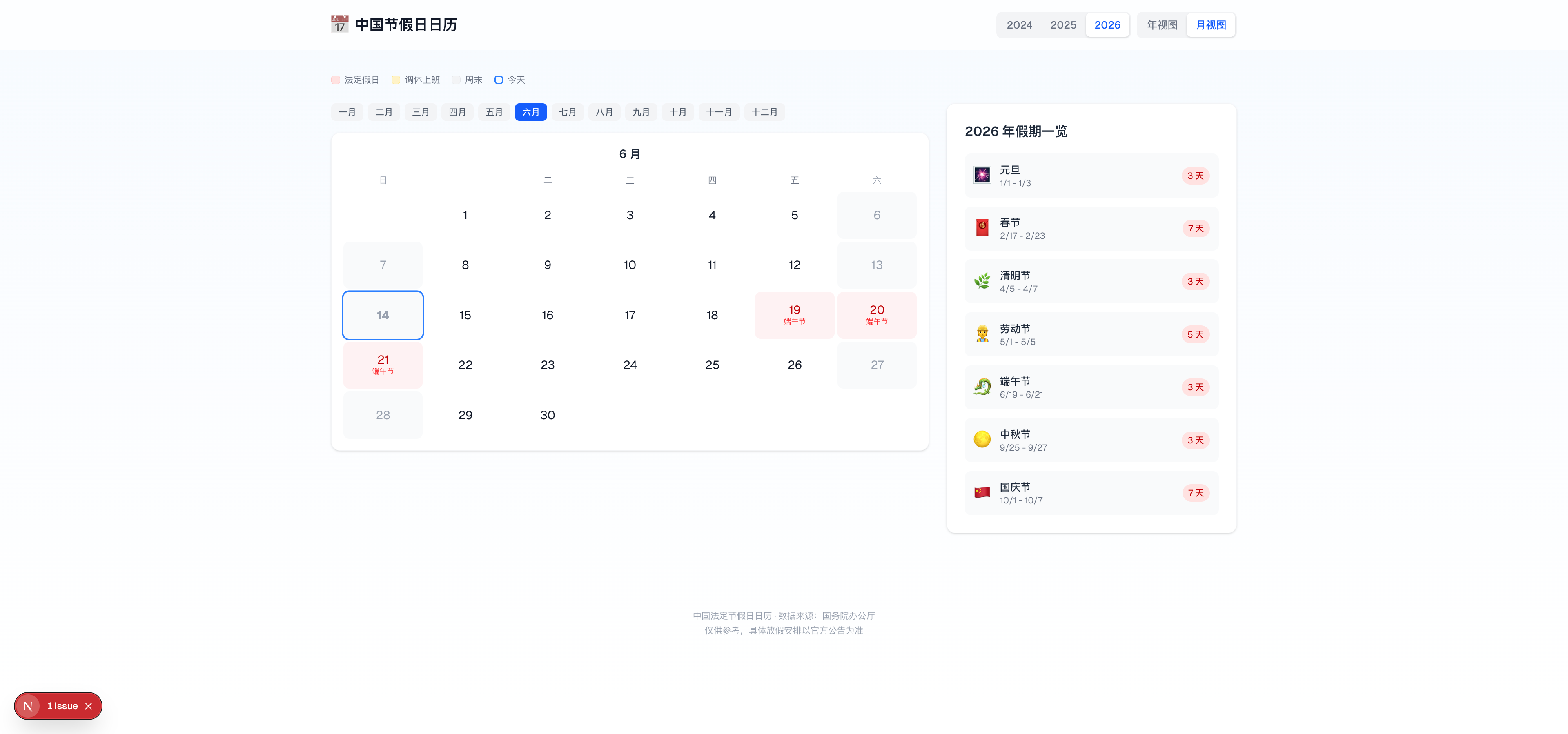
但整体功能相对简单——没有暗色模式切换(至少截图中未体现)、没有节日搜索筛选、没有 FAQ 模块、没有倒计时组件。数据仅覆盖中国法定节假日,没有传统节日、二十四节气等扩展分类。
界面左下角还出现了 1 Issue 的提示,说明构建过程中有小问题没有解决。
公平地说,作为一个初版,它完成了核心功能——能看日历、能查假期。但如果你期待的是 GLM-5.2 那种「一口气把所有细节都补全」的完成度,MiMo 还有差距。
横向对比
任务拆解能力
| 模型 | 是否拆解 | 拆解质量 |
|---|---|---|
| GLM-5.2 | ✅ | 6 大阶段,依赖关系清晰 |
| GLM-5.1 | ⚠️ | 简单规划,直接开写 |
| DeepSeek V4 Pro | ✅ | 完整任务清单,带依赖标注 |
| MiMo V2.5 Pro | ❌ | 未触发任务拆解 |
数据覆盖范围
| 模型 | 国家覆盖 | 节日类型 | 数据量 |
|---|---|---|---|
| GLM-5.2 | 仅中国 | 法定+传统+节气+国际+纪念 | 60+ |
| GLM-5.1 | 仅中国 | 法定+传统+节气+国际+纪念 | 61 |
| DeepSeek V4 Pro | 100+ 国家 | Public/Bank/School/Observance | API 动态获取 |
| MiMo V2.5 Pro | 仅中国 | 法定假日+调休 | ~30 |
界面完成度
| 模型 | 视图模式 | 暗色模式 | 搜索/筛选 | 倒计时 | FAQ |
|---|---|---|---|---|---|
| GLM-5.2 | 月历+年度+近期+详情 | ✅ | ✅ | ✅ | ✅ |
| GLM-5.1 | 月历+列表 | ✅ | ✅ | ✅ | ✅ |
| DeepSeek V4 Pro | Year+List | ✅ | ❌ | ❌ | ❌ |
| MiMo V2.5 Pro | 月视图+年视图 | ❌ | ❌ | ❌ | ❌ |
自我验证
| 模型 | 类型检查 | 构建 | UI 验证 | 渲染内容验证 |
|---|---|---|---|---|
| GLM-5.2 | ✅ | ✅ | ✅ Playwright | ✅ |
| GLM-5.1 | ✅ | ✅ | ❌ | ❌ |
| DeepSeek V4 Pro | ✅ | ✅ | ❌ | ❌ |
| MiMo V2.5 Pro | ❌ | ⚠️ (1 Issue) | ❌ | ❌ |
几点观察
1. GLM 系列的验证逻辑最闭环。 从类型检查、构建验证到 Playwright UI 验证和渲染内容验证,GLM-5.2 是唯一一个做到全链路自我验证的。GLM-5.1 虽然没做 UI 验证,但基础验证也在。这说明智谱在 Agent 的「闭环思维」上确实下了功夫——不只是写完代码,还要确认代码真的跑得对。
2. DeepSeek 的国际化是「天然」的。 其他模型都默认只做中国,DeepSeek 一上来就考虑了多国场景。如果你的项目本身有国际化需求,这是一个显著优势。但代价是没有做 UI 验证,对于追求首版质量的场景,这是个隐患。
3. 任务拆解能力差异明显。 GLM-5.2 和 DeepSeek 都有完整的任务拆解,GLM-5.1 做了简单规划,MiMo 完全跳过了这一步。任务拆解决定了模型能不能在动手前想清楚全局,这直接影响最终产物的完整性。
4. MiMo 适合快速原型。 虽然功能简单,但 MiMo 的核心功能是可用的——日历能看、假期能查。如果你的需求是一个快速 MVP,不需要那么多花哨功能,MiMo 的「直接开干」风格反而有效率优势。
5. 同一提示词,四种路径。 这可能是最有意思的发现。完全相同的输入,四个模型走出了四条不同的路线:GLM 系列重验证、重细节;DeepSeek 重国际化、重视野;MiMo 重速度、重核心。这不只是「谁更强」的问题,而是不同模型有不同的「性格」和「偏好」。
总结
| 维度 | 最强选手 |
|---|---|
| 综合完成度 | GLM-5.2 |
| 国际化视野 | DeepSeek V4 Pro |
| 验证闭环 | GLM-5.2 |
| 快速出活 | MiMo V2.5 Pro |
| 迭代进步幅度 | GLM-5.1 → GLM-5.2 |
如果要我用一句话总结:
GLM-5.2 在「把事情做完整」这件事上最强,DeepSeek 在「把事情做大」这件事上最有想法,MiMo 在「先把核心功能跑起来」这件事上最快。
没有绝对的赢家,只有最适合你需求的那个。
参考链接
昨天的评测:一句话到上线 GLM-5.2 深度实测
(见本公众号历史文章)Claude Code 官方
https://docs.anthropic.com/en/docs/claude-codeGLM-5.2 模型介绍(智谱 AI)
https://chat.zhipuai.cn/DeepSeek 官方
https://www.deepseek.com/Nager.Date API(免费假日数据)
https://date.nager.at/Next.js 15 文档
https://nextjs.org/docs
本文标题:GLM-5.2、GLM-5.1、DeepSeek V4 Pro、小米 MiMo V2.5 Pro 分别做同一个项目效果对比
文章作者:AwesomeYang
发布时间:2026-06-14
最后更新:2026-06-22
原始链接:https://awesomeyang.com/2026/06/14/five-chinese-llm-compare/
版权声明:未经允许禁止转载,请关注公众号联系作者
