别再只想着写 Prompt 了:AI 工程范式的四次跃迁
AI 领域每隔半年就会冒出一个新名词。但这一次,从 Prompt Engineering 到 Loop Engineering 的演进,不是术语通胀,而是一场真正的范式革命。
ChatGPT 刚出来那会儿,所有人都在学怎么写 Prompt。一问一答,讲究的是”措辞的艺术”。
一年后大家发现,光会说话不够了——你得给模型喂什么料?工具怎么接?失败了怎么重试?输出了怎么自动改进?
于是 Prompt Engineering 长出了 Context Engineering,又长出了 Harness Engineering,然后又长出了 Loop Engineering。
这不是学术论文里的概念分层,这是过去六年 AI 工程化的真实演进路径。每一层都是被逼出来的。
当你今天要开发一个 AI Agent 时,到底应该从哪个层面开始设计?本文将系统梳理这四个概念的演进脉络,追溯每个概念的首次提出者和核心观点,并深度剖析推动这一演进的底层逻辑。
先看整体结构图,帮你建立直觉:

🧩 第一层:Prompt Engineering —— 跟模型说话的艺术(2020—2024)
本质:优化单次对话中的措辞,让模型输出更贴近预期。
这是最原始、最直觉的起点。2022 年末 ChatGPT 爆火,大家发现同一个问题换种问法,答案天差地别。
在 Code Agent 场景中: 这一阶段就是我们在网页对话框里让 ChatGPT “帮我写一段实现 XX 功能的 Python 代码”。如果它写错了,我们就再回复一句”报错了,请修改”。这就是典型的单次对话优化。
有人总结出 few-shot(给例子)、chain-of-thought(让模型一步步想)、role-playing(给角色)等技巧。一时间,如何写好一段提示词成为了最热门的技术话题,企业开始招聘”Prompt Engineer”岗位。
溯源与定义
Prompt Engineering 的概念伴随着 2020 年 6 月 OpenAI 发布 GPT-3 而走入大众视野。GPT-3 的论文标题 Language Models are Few-Shot Learners [1] 揭示了其核心洞察:一个足够大的语言模型,仅需少量示例就能学习新任务,而这些示例正是通过 Prompt 来传递的。在 GPT-3 之前,让模型完成新任务需要经历数据标注、模型微调、评估等漫长流程。Prompt Engineering 的出现彻底改变了这一范式——你只需要用自然语言”告诉”模型该做什么。
核心技术与里程碑
2022 年 1 月,Google Brain 团队提出了 Chain-of-Thought (CoT) 提示词技术 [2],通过在提示中加入推理步骤的示例,显著提升了模型在复杂推理任务上的表现。研究者甚至发现,仅仅在提示词末尾加上一句 “Let’s think step-by-step”,就能让模型的推理能力产生质的飞跃。
2023 年 ChatGPT 的爆发将 Prompt Engineering 推向了全民技能的高度。同年 6 月 OpenAI 发布 GPT-4 Function Calling,标志着模型具备了”准确输出结构化参数”的能力,为后续的 Agent 化奠定了基础。
局限性
然而,Prompt Engineering 本质上是单次交互的优化。它关注的核心问题是”怎么问”(How to ask)。
你可以在 prompt 层面让模型「表现得像」某个角色,但角色本身的背景知识和能力不可能凭空产生。
这就像你让一个不认识你的人假装认识你——话说得再漂亮,他也不知道你是谁。当我们开始构建需要多步骤推理、长时间运行、与外部环境交互的 AI Agent 时,仅靠一段精心雕琢的提示词已经远远不够了。
于是需要 Context。
📂 第二层:Context Engineering —— 喂什么远比怎么说重要(2025)
本质:管理和优化模型能看到的信息环境。
2023 年一个关键转折是上下文窗口的指数级扩大。模型不再只有”几句话的记忆”了:
| 模型 | 时间 | 上下文窗口 |
|---|---|---|
| GPT-3.5 | 2022 | 4K |
| GPT-4 | 2023.03 | 8K → 32K |
| Claude 2 | 2023.07 | 100K |
| GPT-4 Turbo | 2023.11 | 128K |
| Gemini 1.5 Pro | 2024.02 | 1M |
上下文窗口越大,喂什么就比怎么说更具决定因素。
溯源与定义
2025 年 6 月 18 日,Shopify CEO Tobi Lütke 发布了一条推文,引爆了这个概念 [3]:
“I really like the term ‘context engineering’ over prompt engineering. It describes the core skill better: the art of providing all the context for the task to be plausibly solvable by the LLM.”
—— Tobi Lütke, 2025年6月18日
一周后(6月25日),前 Tesla AI 总监 Andrej Karpathy 发推强力背书 [4]:
“+1 for ‘context engineering’ over ‘prompt engineering’. People associate prompts with short task descriptions… When in every industrial-strength LLM app, context engineering is the delicate art and science of filling the context window with just the right information for the next step.”
—— Andrej Karpathy, 2025年6月25日
同月,LangChain 创始人 Harrison Chase 在其博客 The rise of context engineering(6月23日)中给出了更精确的技术定义 [5]:
“Context engineering is building dynamic systems to provide the right information and tools in the right format such that the LLM can plausibly accomplish the task.”
随后,Manus 团队(2025 年 7 月)[6] 和 Anthropic(2025 年 9 月)[7] 分别发表了系统性的实践文章,将 Context Engineering 从一个流行术语提升为一套完整的工程方法论。
核心观点
Anthropic 在其文章中明确指出了 Context Engineering 与 Prompt Engineering 的本质区别 [7]:Prompt Engineering 关注的是”怎么写指令”,而 Context Engineering 关注的是”在推理时,模型的上下文窗口里应该有什么”。这包括系统指令、工具定义、MCP 协议、外部数据、消息历史等一切可能影响模型行为的信息。
Anthropic 还提出了一个关键概念——Context Rot(上下文腐烂):随着上下文窗口中 token 数量的增加,模型准确回忆信息的能力会下降。因此,上下文必须被视为一种有限资源,需要精心管理。
业界案例:Manus 的实践
Manus 团队在其博客中分享了多项极具实践价值的 Context Engineering 策略 [6]:
- 围绕 KV-Cache 设计:在其 Agent 系统中,平均输入输出 token 比率约为 100:1。通过保持 prompt 前缀稳定、确保上下文仅追加不修改,他们将推理成本降低了 10 倍。
- 文件系统即上下文:将文件系统作为”终极上下文”——大小无限、天然持久、可由 Agent 自主操作。
- 通过 Recitation 操控注意力:让 Agent 不断重写
todo.md文件,将全局计划”朗诵”到上下文末尾,利用 Transformer 的近因效应来防止目标漂移。
在 Code Agent 场景中: 这一阶段的典型代表是早期的 Cursor 或初版 Claude Code。你不再需要手动把代码复制粘贴给模型,系统会自动把整个项目文件、Git diff、终端的 lint 错误作为上下文喂给模型。模型看到了完整的项目全貌,自然能给出更精准的修改建议。
RAG 的本质,就是工程化的多了一个系统做 context engineering。窗口每扩大一个数量级,Context Engineering 的有效性就上升一个台阶。
但问题来了:就算你给了模型完美上下文,模型还是可能挂掉——API 超时了、工具调用失败了、输出格式不对。这时候你不能指望在 prompt 里加一句”如果失败了就重试”就能搞定。
于是需要 Harness。
🔌 第三层:Harness Engineering —— 为模型穿上外骨骼(2026年初)
本质:围绕模型构建的完整执行系统——工具调用、安全护栏、错误处理、状态管理、多模型路由。
2026 年初,随着 AI Coding Agent 的大规模应用,一个新的工程挑战浮出水面:如何让 Agent 在无人监督的情况下可靠地完成工作?人们发现,一个”会调用工具的模型”和”一个稳定的 Agent 系统”之间隔着天堑。
溯源与定义
2026 年 2 月 5 日,HashiCorp 联合创始人 Mitchell Hashimoto 在其博客文章 My AI Adoption Journey 中首次使用了 “Harness Engineering” 这个术语 [8],描述了他如何通过设计环境来引导 Agent 行为。
六天后(2月11日),OpenAI 发表了 Harness engineering: leveraging Codex in an agent-first world [9],描述了一个团队如何在 5 个月内以”零手写代码”的方式,完全依靠 Codex Agent 构建了约百万行级别的产品,合并了约 1500 个 PR。
2026 年 2 月 17 日,Thoughtworks 杰出工程师 Birgitta Böckeler 在 martinfowler.com 上发表了关于 Harness Engineering 的初始备忘录 [10],并在 4 月 2 日发表了完整的系统性文章。
2026 年 3 月 10 日,LangChain 的 Vivek Trivedy 发表了 The Anatomy of an Agent Harness [11],给出了那个被广泛引用的公式:
Agent = Model + Harness. If you’re not the model, you’re the harness.
—— Vivek Trivedy, LangChain, 2026年3月10日
2026 年 4 月 19 日,Google 工程总监 Addy Osmani 发表了 Agent Harness Engineering [12],进一步总结和传播了这一概念。
核心框架
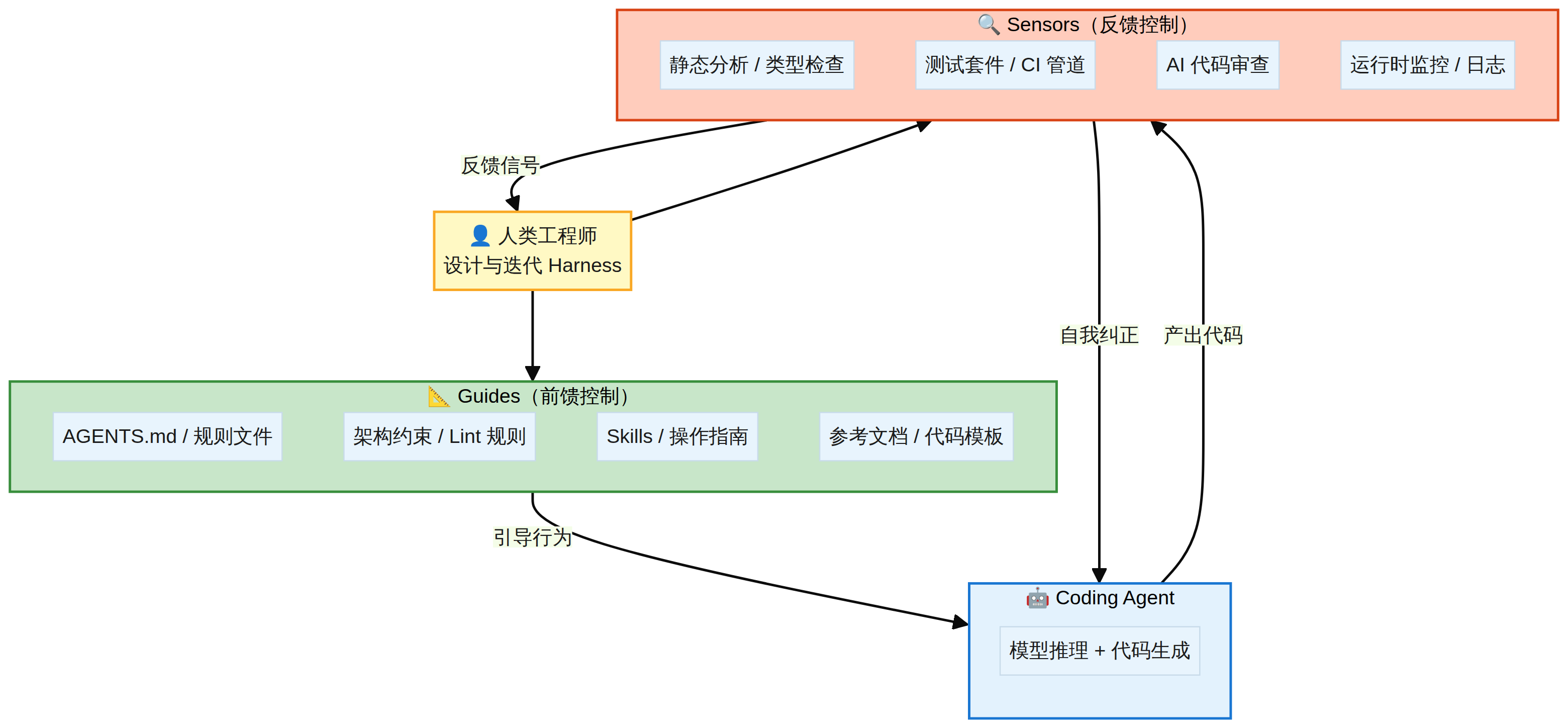
Birgitta Böckeler 在 martinfowler.com 上提出了 Harness 的核心框架。Harness 由两大类组件构成:
Guides(前馈控制)——在 Agent 行动之前预测并引导其行为,提高首次正确率。包括 AGENTS.md 规则文件、架构约束、Skills 操作指南、参考文档和代码模板等。
Sensors(反馈控制)——在 Agent 行动之后观察结果并帮助其自我纠正。包括静态分析/类型检查、测试套件/CI 管道、AI 代码审查、运行时监控/日志等。
每种控制又分为两个执行类型:Computational(确定性的,由 CPU 执行,快速可靠)和 Inferential(语义分析,由 GPU 执行,更慢但能处理模糊问题)。
核心理念:”棘轮机制”
Addy Osmani 在其文章中提炼了 Harness Engineering 最重要的实践原则 [12]:
“A decent model with a great harness beats a great model with a bad harness… The most important habit in harness engineering is treating agent mistakes as permanent signals. Every line in a good AGENTS.md should be traceable back to a specific thing that went wrong.”
这就是所谓的棘轮机制(Ratchet):每当 Agent 犯一次错,就工程化一个解决方案,确保它永远不再犯同样的错误。这不是”等下一代模型来修复”的心态,而是”当下就解决”的工程师思维。
业界案例:OpenAI 的”零手写代码”实验
OpenAI 团队在其文章中描述了一个令人震撼的实践 [9]:他们设定了一个极端约束——“no manually typed code at all”。工程师们通过设计 Harness 和反馈循环,引导 Codex Agent 产出了约 100 万行代码。他们的核心经验是:
“When the agent struggles, we treat it as a signal: identify what is missing — tools, guardrails, documentation — and feed it back into the repository.”
在 Code Agent 场景中: 这一阶段就是给 Code Agent 穿上护栏。比如编写 AGENTS.md 规则文件(Guides),让 Agent 知道代码规范;或者在 Agent 修改代码后,强制运行测试套件(Sensors),只有测试通过才允许提交。如果测试失败,Agent 会看到报错并自我纠正,整个过程在沙箱隔离环境中进行。
模型本身的可重复性是 0%。同一个 prompt,相同温度和 seed,模型输出也可能不同。如果你的系统依赖”模型每次都完美执行”,那你的系统在第一天就不可靠了。Harness 就是把这个不可靠性关在笼子里的工程手段。
🔁 第四层:Loop Engineering —— 一次完美不重要,持续改进才重要(2026年6月)
本质:让系统形成”执行 → 评估 → 反馈 → 调整”的自动闭环,人类只设计循环,不参与执行。
前面三层解决的是”一次对话/一次任务”的问题。但现实世界中的系统需要持续运转——今天好不代表明天好。用户反馈变了、数据分布漂移了、模型升级了……如果没有反馈循环,系统会无声地劣化。
溯源与定义
2026 年 6 月 7 日,Peter Steinberger 的一条推文获得了超过 800 万次浏览,引爆了 Loop Engineering 的讨论 [13]:
“Here’s your monthly reminder that you shouldn’t be prompting coding agents anymore. You should be designing loops that prompt your agents.”
—— Peter Steinberger, 2026年6月7日
几乎同时,Anthropic Claude Code 的负责人 Boris Cherny 在公开场合表示 [14]:
“I don’t prompt Claude anymore. I have loops running that prompt Claude and figuring out what to do. My job is to write loops.”
—— Boris Cherny, Head of Claude Code at Anthropic
同日,Addy Osmani 发表了系统性的长文 Loop Engineering [15],正式为这一概念命名并给出了完整的框架定义:
“Loop engineering is replacing yourself as the person who prompts the agent. You design the system that does it instead.”
核心架构
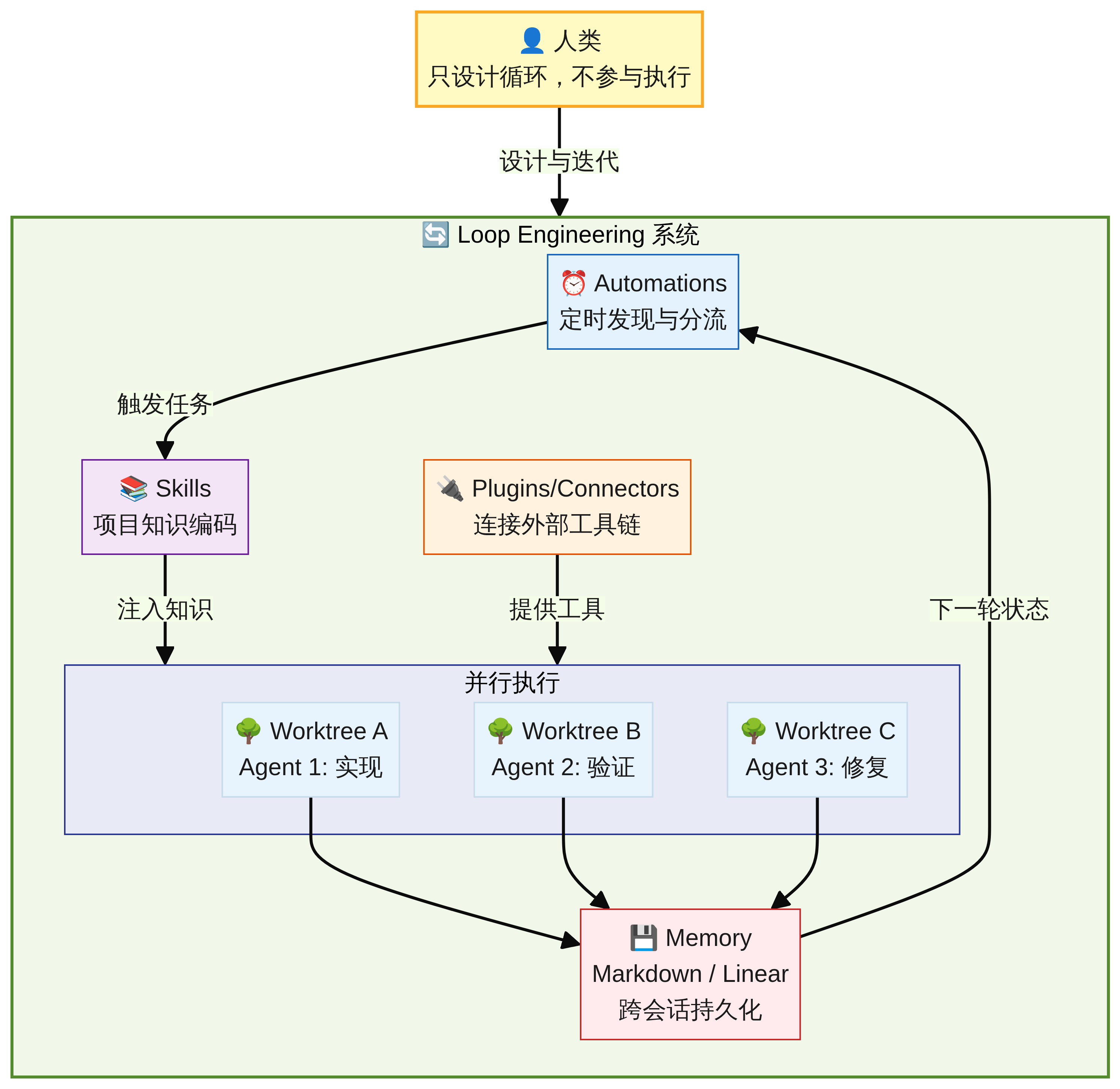
Addy Osmani 指出,Loop Engineering 位于 Harness Engineering “之上一层”——Harness 定义了单个 Agent 运行的环境,而 Loop 则让这个环境自动运转、自我驱动 [15]:
“Loop engineering sits one floor above the harness. The harness makes the environment one single agent runs inside. The loop runs that harness on a timer, spawns little helpers, and feeds itself.”
一个完整的 Loop 需要五个核心组件加一个持久化层:
| 组件 | 职责 | 实现示例 |
|---|---|---|
| Automations | 定时触发,发现和分流工作 | Codex Automations、GitHub Actions |
| Worktrees | 隔离并行工作,防止冲突 | Git Worktree,每个 Agent 独立分支 |
| Skills | 编码项目知识,避免重复解释 | SKILL.md 文件,按需加载 |
| Plugins/Connectors | 连接真实工具链 | MCP 服务器,Linear/Slack 集成 |
| Sub-agents | 分离创建者与检查者 | 实现 Agent + 验证 Agent + 安全审查 Agent |
| Memory | 跨会话持久化状态 | Markdown 文件、进度文件 |
如果说 Harness 是”工厂车间的设备和安全规程”,那么 Loop 就是”让整个工厂 24/7 自动运转的调度系统”。
在 Code Agent 场景中: 这是目前的最高形态。比如 OpenAI Codex 的 Automations [16] 或 Claude Code 的 /loop 命令 [17]。你不再需要手动唤醒 Agent 帮你看代码,而是设定一个定时循环任务:Agent 每天凌晨自动拉取最新代码,运行代码巡检,发现潜在的 issue 并自动修复,甚至自动提交 PR。它在后台 24/7 不知疲倦地工作。
用一个比喻:Prompt Engineering 是告诉学生答题时先审题,Context Engineering 是给全套开卷资料,Harness Engineering 是设计考场的防作弊和监考规则,Loop Engineering 是把考试分数用来修改下学期教学大纲。
⏳ 为什么会这样演进?
这四个概念并非互相替代,而是层层包含、逐级抽象的关系。Prompt Engineering 是 Context Engineering 的子集(提示词只是上下文的一部分);Context Engineering 是 Harness 的一个方面(上下文管理只是 Harness 的组成部分之一);而 Loop Engineering 则是让整个 Harness 自动运转的编排层。
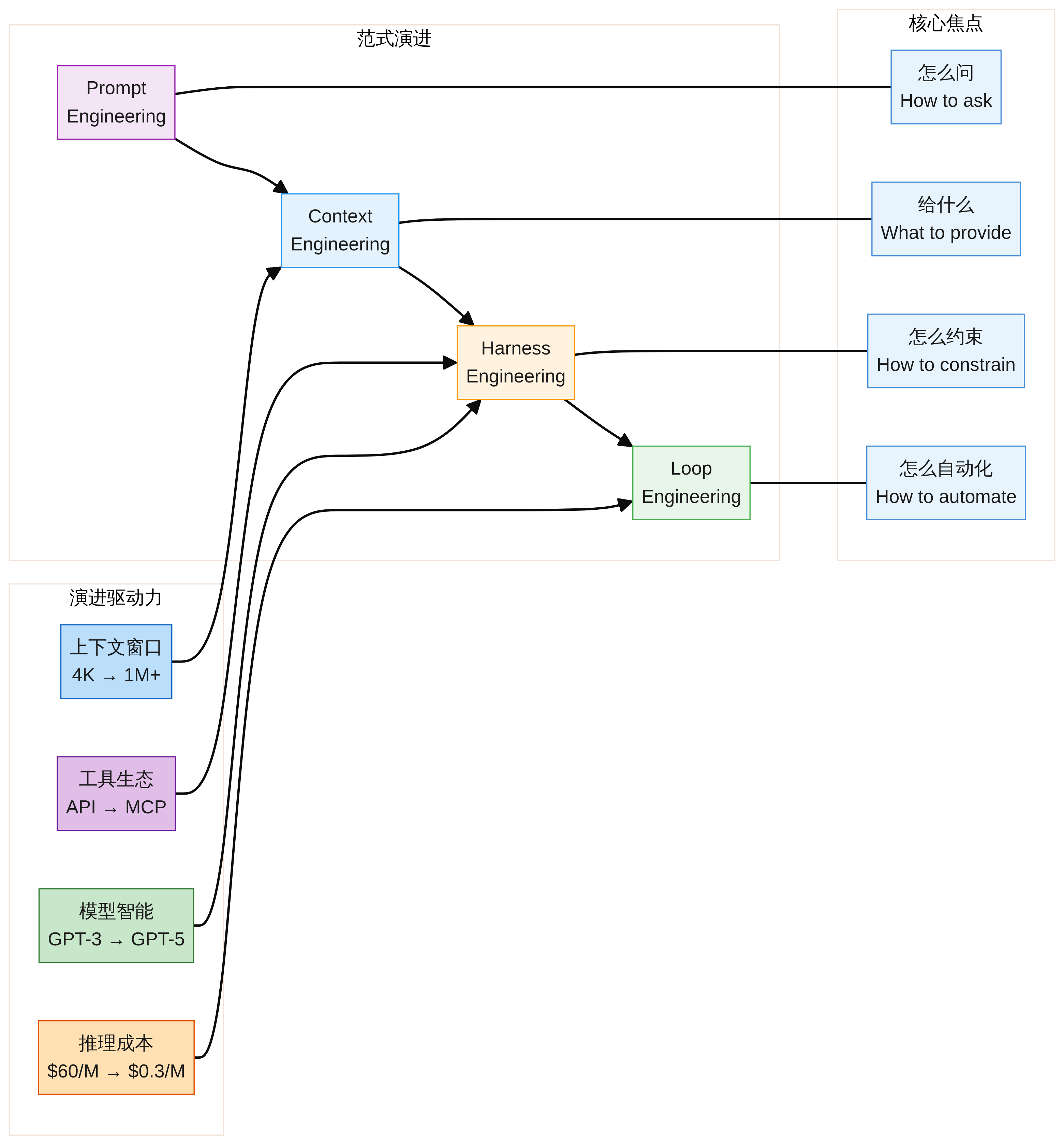
每一层的出现都是因为上一层不够用了。这背后有四个底层驱动力:
| 驱动力 | 变化趋势 | 催生的范式 | 逻辑关系 |
|---|---|---|---|
| 上下文窗口 | 4K → 1M+ | Context Engineering | 窗口大了,管理上下文成为核心挑战 |
| 高缓存命中 | Prompt Caching 普及 | Context Engineering | 长上下文重复调用成本暴降,使海量 Context 实用化 |
| 模型智能 | GPT-3 → V4/GPT-5 | Harness Engineering | 模型越强,可委托的任务越复杂,越需要护栏 |
| 推理成本 | $60/M → $0.0028/M | Loop Engineering | 成本断崖式下降,让 Agent 24/7 循环运行变得廉价 |
| 工具生态 | API → MCP | Harness Engineering | 基础设施成熟,Agent 才能与真实世界交互 |
第一次跃迁(Prompt → Context) 的核心驱动力是上下文窗口的扩大与高缓存命中(Prompt Caching)的普及。当窗口只有 4K tokens 时,你确实只需要关心那一小段 Prompt。但当窗口扩大到 1M,且 Anthropic、OpenAI 和 DeepSeek 等厂商纷纷推出缓存折扣(如 OpenAI Cached Tokens 享 50% 折扣 [18])后,将海量项目代码作为固定上下文的成本大幅降低,这使得 Context Engineering 在工程上变得实用。
第二次跃迁(Context → Harness) 的核心驱动力是模型智能的提升和工具生态的成熟。当模型足够聪明,能够使用工具、执行代码、与环境交互时,它就不再是一个”回答问题的聊天机器人”,而是一个”执行任务的 Agent”。Agent 需要执行环境、安全边界、反馈循环——这就是 Harness。
第三次跃迁(Harness → Loop) 的核心驱动力是推理成本的断崖式下降与性能的不降反升。以 2026 年发布的 DeepSeek V4 为例,其 SWE-bench Verified 跑分高达 80.6% [19],超越了诸多前代旗舰模型;更震撼的是其价格,V4 Flash 的缓存命中输入成本暴降至每百万 token 仅 $0.0028 [20]。当成本从几年前的 $60 降到几美分,让 Agent 24/7 循环运行、反复试错直至成功,在经济上不仅可行,甚至比雇佣初级程序员更划算。
🎯 开发一个 Agent 前,应该怎么设计?
基于这四层演进,我建议按这个顺序思考,而不是一上来就敲代码:
Step 1:明确”外脑有多重要”
你的 Agent 需要多大程度的 AI?如果只需要一句 prompt 就能搞定,那可能只用 Prompt Engineering 就够了。如果依赖大量领域知识,投资 Context Engineering。
Step 2:画清”边界”
哪些必须人确认?哪些可以全自动?错误发生后怎么办?这就是 Harness 的边界设计——不是”把最智能的模型放进去”,而是”在最需要智能的地方放最合适的模型,在最需要安全的地方放护栏”。
Step 3:设计”反馈回路”
上线后我靠什么知道它在变好还是变差?多久评估一次?谁来评估(LLM / 人工 / 用户行为指标)?反馈怎么汇入系统改进?
一个实用框架:
- 先从最简单的 Prompt 开始
- 如果不够 → 加 Context(RAG / 记忆)
- 如果还不够 → 加 Harness(工具 / 护栏 / 错误处理)
- 如果跑起来了 → 加 Loop(评估 / 反馈 / 改进)
不要超前设计。 90% 的场景可能只需要 Prompt + 少量 Context。不要一上来就搭 Loop。
正如 OpenAI 团队在其实践中总结的 [9]:
“Early progress was slower than we expected, not because Codex was incapable, but because the environment was underspecified. The agent lacked the tools, abstractions, and internal structure required to make progress toward high-level goals.”
💭 写在最后
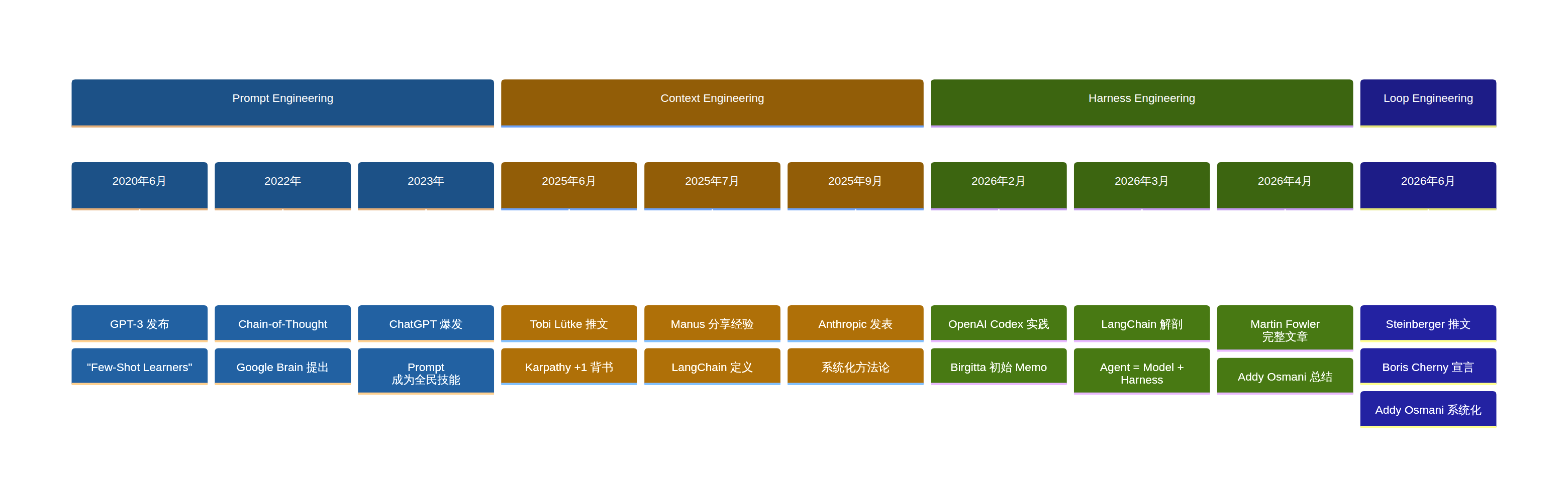
这几个概念之所以让人困惑,不是因为它们有多深奥,而是因为它们出现得太快——六年内从 Prompt 走到 Loop,每一层刚被社区理解,下一层就已经在行业里流行了。
但回头看这个演进很理性:
- Prompt Engineering = 怎么表达(How to ask)
- Context Engineering = 怎么喂信息(What to provide)
- Harness Engineering = 怎么约束(How to constrain)
- Loop Engineering = 怎么自动化(How to automate)
从 Expression → Information → System → Evolution。
这是 AI 工程化的自然递进,而不是什么炒作新名词。当你开始开发一个 Agent 系统时,我的建议很简单:先用 Prompt 试,发现不够了再加 Context,系统不稳定了再画 Harness,跑通之后再上 Loop。
每一层的出现都是因为上一层不够用了。 这既是历史,也是方法论。
虾仔 · 一个游得快、反应快的数字虾米
参考资料
[1] Tom B. Brown et al., “Language Models are Few-Shot Learners”, OpenAI, arXiv:2005.14165, May 28, 2020. https://arxiv.org/abs/2005.14165
[2] Jason Wei et al., “Chain-of-Thought Prompting Elicits Reasoning in Large Language Models”, Google Brain, arXiv:2201.11903, Jan 28, 2022. https://arxiv.org/abs/2201.11903
[3] Tobi Lütke, Twitter/X, June 18, 2025. https://x.com/tobi/status/1935533422589399127
[4] Andrej Karpathy, Twitter/X, June 25, 2025. https://x.com/karpathy/status/1937902205765607626
[5] Harrison Chase, “The rise of context engineering”, LangChain Blog, June 23, 2025. https://www.langchain.com/blog/the-rise-of-context-engineering
[6] Yichao ‘Peak’ Ji, “Context Engineering for AI Agents: Lessons from Building Manus”, Manus Blog, July 18, 2025. https://manus.im/blog/Context-Engineering-for-AI-Agents-Lessons-from-Building-Manus
[7] Anthropic Engineering, “Effective context engineering for AI agents”, September 29, 2025. https://www.anthropic.com/engineering/effective-context-engineering-for-ai-agents
[8] Mitchell Hashimoto, “My AI Adoption Journey”, mitchellh.com, February 5, 2026. https://mitchellh.com/writing/my-ai-adoption-journey
[9] Ryan Lopopolo, “Harness engineering: leveraging Codex in an agent-first world”, OpenAI Engineering, February 11, 2026. https://openai.com/index/harness-engineering/
[10] Birgitta Böckeler, “Harness engineering for coding agent users”, martinfowler.com, April 2, 2026. https://martinfowler.com/articles/harness-engineering.html
[11] Vivek Trivedy, “The Anatomy of an Agent Harness”, LangChain Blog, March 10, 2026. https://www.langchain.com/blog/the-anatomy-of-an-agent-harness
[12] Addy Osmani, “Agent Harness Engineering”, addyosmani.com, April 19, 2026. https://addyosmani.com/blog/agent-harness-engineering/
[13] Peter Steinberger, Twitter/X, June 7, 2026. https://x.com/steipete/status/2063697162748260627
[14] Boris Cherny, Head of Claude Code at Anthropic, public statement, June 2026. https://x.com/rohanpaul_ai/status/2063289804708835412
[15] Addy Osmani, “Loop Engineering”, addyosmani.com, June 7, 2026. https://addyosmani.com/blog/loop-engineering/
[16] OpenAI, “Automations - Codex app”, OpenAI Developers. https://developers.openai.com/codex/app/automations
[17] Verdent AI, “How to Use Claude Code /loop to Automate Dev Workflows”, March 9, 2026. https://www.verdent.ai/guides/claude-code-loop-command
[18] OpenAI, “API Pricing”, openai.com. https://openai.com/api/pricing/
[19] Lightning AI, “DeepSeek V4 Alters Everything We Knew About Price-Performance”, April 26, 2026. https://lightning.ai/blog/deepseekv4comparison
[20] DeepSeek, “Models & Pricing”, DeepSeek API Docs. https://api-docs.deepseek.com/quick_start/pricing
本文标题:别再只想着写 Prompt 了:AI 工程范式的四次跃迁
文章作者:AwesomeYang
发布时间:2026-06-16
最后更新:2026-06-22
原始链接:https://awesomeyang.com/2026/06/16/ai-engineering-four-paradigms/
版权声明:未经允许禁止转载,请关注公众号联系作者
